The Ultimate Guide to Creative Testing in 2026

Creative testing is the discipline of running controlled experiments on your ad creative so you know which hooks, visuals, formats, and offers actually move performance. This guide gives you a repeatable framework you can run on Meta, Google, or any paid channel, from forming a hypothesis to systematizing winners into playbooks. By the end, you will be able to design a clean test, set a defensible sample size, read results with statistical confidence, and decide what to kill or scale.
Quick answer: Creative testing is a structured process for comparing ad creative variations against a single isolated variable to find what drives better outcomes against a KPI like ROAS or CPA. You change one element at a time (the hook, the visual, the format, the angle, or the offer), give each variant enough budget and time to reach statistical significance, then keep the winner and kill the rest. Done consistently, it turns creative from a guessing game into a compounding asset.
Why creative testing decides your account performance
On most paid accounts, creative is the single biggest lever you control. Targeting has flattened as platforms moved to broad signals and automation like Advantage+, so the ad itself does most of the heavy lifting now.
That shift means a sloppy testing process directly caps your results. If you cannot tell a real winner from random noise, you scale the wrong ads and starve the right ones.
A good creative testing system fixes three problems at once. It tells you what works, it tells you why, and it gives you a backlog of proven patterns to reuse. The "why" is what separates a real program from random A/B testing of ads.
What you need before you start
You cannot run clean tests without a few things in place first. Skipping these is the most common reason creative testing produces ambiguous results.
- Ad account history with conversion tracking. You need a working pixel or conversions API and enough recent conversion volume that the platform can optimize. Without it, you are testing in the dark.
- A naming convention. Every ad, ad set, and campaign needs a consistent name that encodes the variable being tested (for example,
Q2_Hook-A_UGC_15s). You cannot analyze what you cannot filter. - A test budget you can commit. Decide a fixed monthly amount for testing that is separate from your scaling budget. Testing is a line item, not an afterthought.
- A hypothesis backlog. Keep a running list of ideas, each written as a testable statement. A backlog stops you from launching random creative and forces every test to answer a question.
Done looks like this: a tracking setup you trust, a naming scheme written down, a fixed test budget, and at least ten hypotheses queued.
Step 1 - Form a testable hypothesis
Every test starts with a hypothesis, not a creative. A hypothesis is a sentence in the form "If we change X, then Y will improve, because Z."
For example: "If we open with a problem-agitation hook instead of a product shot, then hook rate will rise, because the audience is solution-aware and reacts to pain points." That single sentence tells you the variable, the metric, and the reasoning.
Write your hypothesis before you brief a single asset. It keeps the test honest and it makes the result reusable, because a confirmed hypothesis becomes a rule you apply across future creative.
Pro tip: Rank your backlog by expected impact and ease, not by what is easiest to produce. Test the boldest, highest-impact ideas first, because incremental tweaks rarely move an account.
Done looks like this: a written hypothesis with a clear variable, a target metric, and a reason.
Step 2 - Choose the one variable to isolate
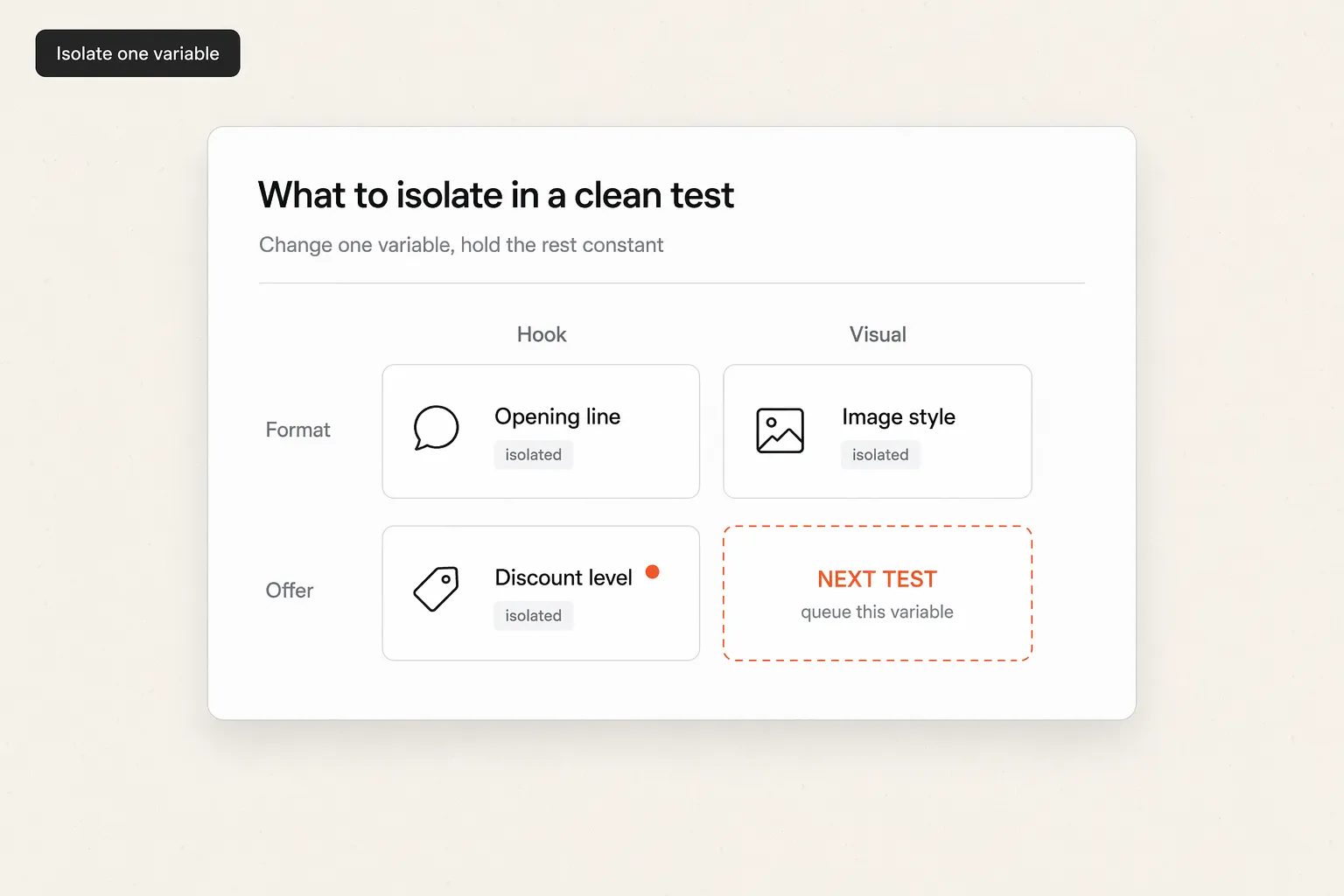
A clean test changes exactly one thing. If you swap the hook and the visual at the same time, a win tells you nothing about which change caused it.
Pick a single variable from this hierarchy, working roughly top to bottom by impact. The hook and the core angle usually move performance far more than a CTA tweak or a color change.
| Variable to isolate | What it controls | Primary metric to watch | Decision rule |
|---|---|---|---|
| Hook (first 3 seconds) | Whether anyone stops | Hook rate, thumb-stop ratio | Keep the variant with materially higher hook rate at equal spend |
| Angle / message | Who you speak to and why | CTR, CPA | Keep the angle with lower CPA at significance |
| Visual / format | Static vs UGC vs motion | Hold rate, CTR | Keep the format holding attention and driving clicks |
| Offer | The deal itself | CPA, ROAS | Keep the offer with stronger ROAS, watch margin |
| CTA / copy | The closing ask | CTR, conversion rate | Keep only on a clear, significant lift |
If you want a deeper breakdown of how individual elements perform, see Creative Performance Analysis for an element-level view.
Done looks like this: one variable chosen, everything else held constant across variants.
Step 3 - Structure the test
Now decide how the test runs inside the platform. The two structural choices that matter most are budget allocation and audience.
For budget, you are choosing between ABO and CBO. ABO (ad set budget optimization) gives each variant its own fixed budget, which guarantees every creative gets a fair, equal share of spend. CBO (campaign budget optimization) lets the platform shift budget toward early front-runners, which is efficient for scaling but biased for testing, because it can starve a variant before it has data.
For pure creative testing, ABO is usually the cleaner choice because it protects equal spend per variant. Use one ad set per variant, the same audience, and the same placements. Reserve CBO and broad Advantage+ setups for the scaling phase, after a winner is proven. Meta documents how these budget options behave in its Business Help Center.
Keep the audience broad and identical across variants so the creative, not the targeting, is what differs. A narrow audience adds noise and slows down significance.
Pro tip: Run no more than four to six variants per test on a mid-size budget. Too many variants split spend so thin that none reaches significance, and you end up with six inconclusive ads instead of one clear answer.
Done looks like this: ABO structure live, one variant per ad set, identical audience and placements, equal budgets.
Step 4 - Set sample size, duration, and significance
This is the step most marketers skip, and it is why most "winners" do not hold up. A result is only trustworthy when each variant has enough data to rule out luck.
Decide three numbers before launch: minimum spend per variant, minimum conversions per variant, and minimum run time. As a rule of thumb, aim for at least 50 conversions per variant before you call a winner on CPA or ROAS, and run for at least three to four days to clear the platform learning phase and weekday-weekend swings. For upper-funnel metrics like hook rate, you can read signal faster because impressions accumulate quickly.
| Test budget per variant | Typical use case | Minimum run time | What you can reliably read |
|---|---|---|---|
| 20 to 50 USD/day | Low-volume or niche accounts | 5 to 7 days | Hook rate, CTR, early CPA signal |
| 50 to 150 USD/day | Most mid-market accounts | 4 to 5 days | CPA and CTR with moderate confidence |
| 150 USD+/day | High-volume accounts | 3 to 4 days | ROAS and CPA at statistical significance |
Statistical significance means the difference between variants is unlikely to be random chance, usually expressed as a 90 to 95 percent confidence level. If your test has tiny numbers, no confidence level will save it. For the logic on sample size, the Evan Miller sample size calculator is a useful reference, and Google outlines experiment principles in its Ads experiments documentation.
Done looks like this: a pre-set minimum spend, conversion count, and run time written next to the test, with a target confidence level.
Step 5 - Read the results and decide
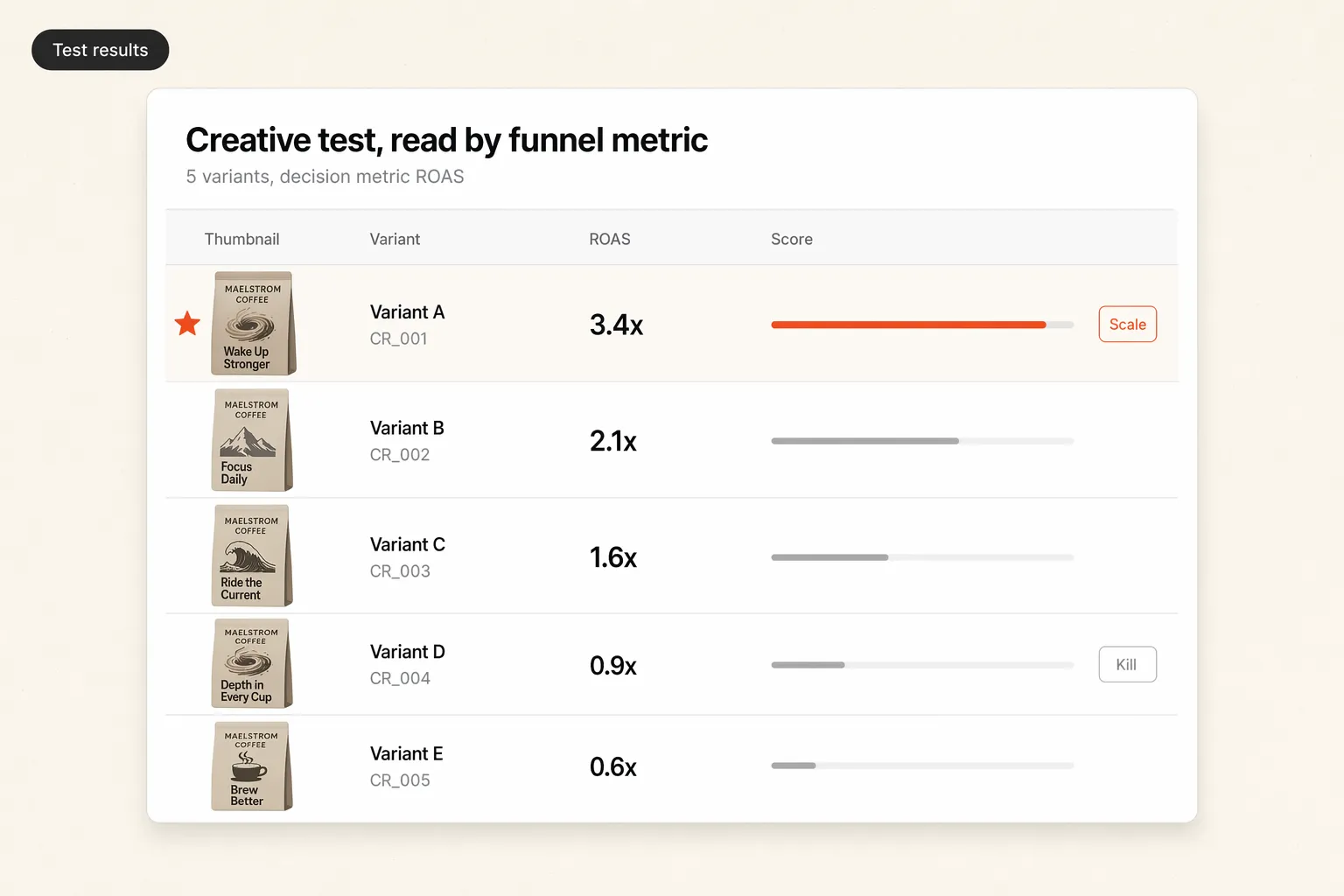
When the test hits your thresholds, read the metrics in funnel order. Each metric tells you about a different stage, and reading them in sequence shows you where a creative wins or breaks.
- Hook rate and thumb-stop ratio tell you if the opening stops the scroll. A low hook rate means the first three seconds failed, regardless of everything after.
- Hold rate tells you if people stay past the hook. A strong hook with a weak hold means the body lost them.
- CTR tells you if the ad earns the click. It bridges attention and intent.
- CPA and ROAS tell you if the click turns into profitable action. These are your decision metrics for most accounts.
Watch CPM as a sanity check on auction costs, but do not optimize creative to CPM. For context on the top-of-funnel metric, Hook Rate breaks down what a good number looks like by format.
Apply clear kill-and-scale rules. Kill any variant that is meaningfully worse than the control at significance, or that fails to clear hook rate after enough impressions. Scale the winner gradually into your CBO or Advantage+ scaling campaign, and watch that performance holds as spend rises. Benchmarks help you judge "good," so compare against figures like the ones in Average ROAS for eCommerce Benchmarks.
This is also where asking "why is this working" pays off, because element-level diagnosis turns a single winning ad into a transferable insight. Hawky's Creative Analysis scores hook, visual, and CTA performance separately, and its Copilot returns "why is this working" breakdowns with citations, so the lesson carries into the next round of creative.
Done looks like this: a documented decision per variant (kill, keep, or scale) with the metric and confidence level that justified it.
Step 6 - Systematize winners into playbooks
A winning ad is worth one campaign. A winning pattern is worth a hundred. The point of creative testing is to extract the rule behind the win and write it down.
Turn each confirmed hypothesis into a playbook entry: the variable, the result, and the rule it produced (for example, "problem-agitation hooks beat product-shot hooks for solution-aware audiences by roughly 20 percent on hook rate"). Tag winners by hook type, format, and angle so your next brief starts from proven patterns instead of a blank page.
This is where creative iteration compounds. Each test makes the next brief smarter, because you are building a library of what works for your specific audience. The best winning creative usually comes from iterating on a proven angle, not from starting over every time.
Done looks like this: a living playbook of proven patterns, tagged and searchable, feeding your next briefs.
Step 7 - Manage creative fatigue and keep the loop running
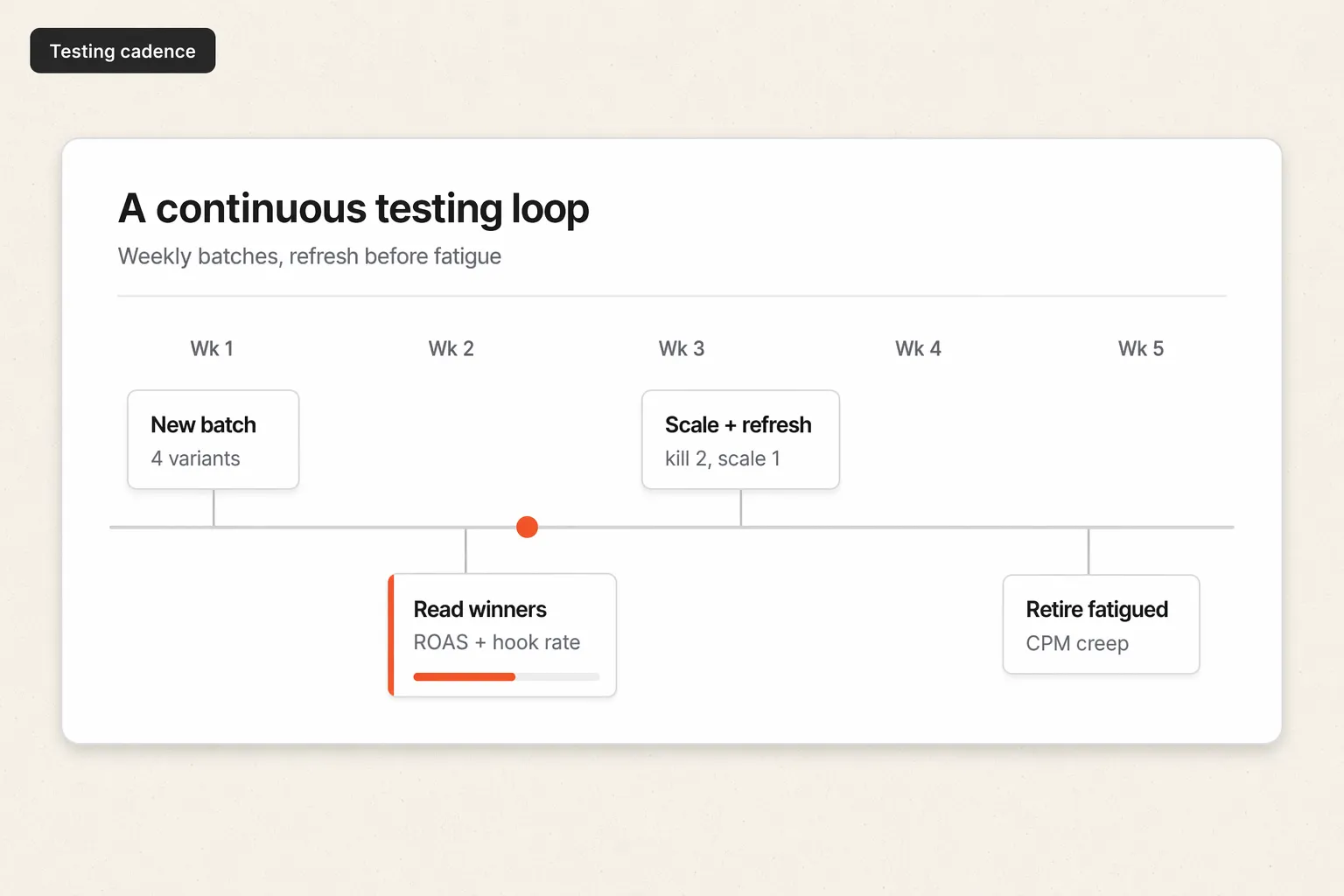
Winners do not win forever. As frequency rises, the same audience sees the ad too often, response drops, and CPA creeps up. That decay is creative fatigue, and it is the reason testing is never finished.
Watch for the signals: rising frequency, falling CTR and hold rate, and climbing CPM and CPA on a once-strong ad. When you see them, rotate in fresh variants from your playbook before the winner fully decays, so you never run out of proven creative. Creative Fatigue Explained covers the warning signs and refresh cadence in detail.
The loop is continuous: hypothesis, isolate, structure, size, read, systematize, refresh. Run it on a steady cadence and creative stops being a fire drill.
Done looks like this: a fatigue-monitoring habit and a standing pipeline of fresh variants ready to deploy.
Common creative testing mistakes to avoid
Even disciplined teams fall into the same traps. These five cost the most.
- Calling winners too early. A variant looks ahead on day one and gets crowned before it has data. The fix: never declare a result until you hit your pre-set minimum conversions and run time.
- Testing more than one variable at once. You change the hook and the visual together, and a win tells you nothing about cause. The fix: isolate one variable per test, always.
- Using CBO for testing. The platform shifts budget to an early front-runner and starves variants that needed more time. The fix: use ABO with equal budgets for testing, save CBO for scaling.
- Too many variants on too little budget. Six creatives split a small budget so thin that none reaches significance. The fix: cap variants at four to six and match the count to your spend.
- No system for winners. You find a great ad, scale it, and forget why it worked. The fix: log every confirmed hypothesis as a playbook rule so the insight compounds.
Tools that make creative testing easier
You can run this whole framework manually with spreadsheets and the native ads manager. Tools mainly save time on analysis, naming hygiene, fatigue alerts, and producing the next round of variants.
- Native ad platforms (Meta Ads Manager, Google Ads). Where the tests actually run, with built-in budget structures and basic experiment tools. The limitation is manual analysis and no element-level diagnosis.
- Spreadsheets and BI dashboards. Fine for tracking results and significance math, but slow and easy to let go stale.
- Creative analytics tools. This category surfaces element-level metrics like hook rate and hold rate and ranks creative by performance. For a survey of options, see Best Ad Creative Analysis Tools and Best Tools to Evaluate Creative Performance.
- Hawky. As an agentic performance marketing platform, Hawky handles the most steps of this framework in one place. Its Performance Agent runs the closed loop of test, track, optimize, and scale against your KPI, with every move logged with a confidence score and made one-click reversible. Its Creative Agent reads past winners and portfolio gaps from FeatherDB and renders on-brand variants for a specific ad set, so the next test is briefed from proven patterns. The autonomy is configurable, from shadow mode to approval-gated to fully autonomous, with the same audit trail and spend-cap guardrails at every level.
The honest take: tools shorten the loop, but the framework produces the results. A disciplined manual process beats an expensive tool used without one.
Frequently asked questions
What is creative testing?
Creative testing is the process of running controlled experiments on ad creative to find which versions perform best against a KPI such as ROAS or CPA. You isolate one variable (the hook, visual, format, angle, or offer), give each variant equal budget and enough time to reach statistical significance, then keep the winner and kill the rest. The goal is to replace guesswork with a repeatable method that improves creative over time.
How long should you run a creative test?
Run a creative test long enough to collect a defensible sample, usually at least three to five days and enough spend to clear the platform learning phase. For decision metrics like CPA and ROAS, aim for roughly 50 conversions per variant before calling a winner. Upper-funnel metrics like hook rate accumulate faster, so you can read early signal sooner, but final spend and conversion decisions should wait for your pre-set thresholds.
How much budget do you need to test a creative?
Enough that each variant reaches your minimum conversion and spend targets within a reasonable window. On most mid-market accounts that means roughly 50 to 150 USD per variant per day over four to five days, while high-volume accounts can read ROAS confidently faster. Low-volume accounts can test on less but should expect longer run times and lean on upper-funnel signals like hook rate and CTR.
What metrics matter most in creative testing?
Read metrics in funnel order: hook rate and thumb-stop ratio for attention, hold rate for retention, CTR for intent, and CPA and ROAS for profitable outcomes. The upper-funnel metrics diagnose where a creative wins or breaks, while CPA and ROAS are the decision metrics for most accounts. Watch CPM as a cost sanity check, but do not optimize creative to it.
How many creatives should you test at once?
Cap each test at roughly four to six variants on a mid-size budget so spend is not split too thin to reach significance. The right number depends on your budget: more spend supports more variants, less spend means fewer. Testing too many at once produces several inconclusive results instead of one clear, trustworthy winner.
Creative testing is not a one-time project. It is a loop you run on a steady cadence, and every cycle should make your next brief smarter and your account harder to beat. Treat it as a system, log what works, and refresh before fatigue sets in.
If running that loop by hand (forming hypotheses, holding spend equal, reading significance, and refreshing winners before they decay) is eating your week, Hawky's Performance Agent is built for that job.
Ready to hire your first AI performance team? Book Demo




